※本記事では、課題のネタバレを含みます。
RPA Challengeとは
RPA Challengeは、UiPath社が公開している「RPAで顧客データを入力フォームに自動登録し、その正解率と処理速度を計測する」というものです。

「EXCELファイルをダウンロード」のボタンをクリックすると、デモ用の顧客データ(.xlsx)がダウンロード出来ます。
Excelのレイアウトは以下のようになっています。
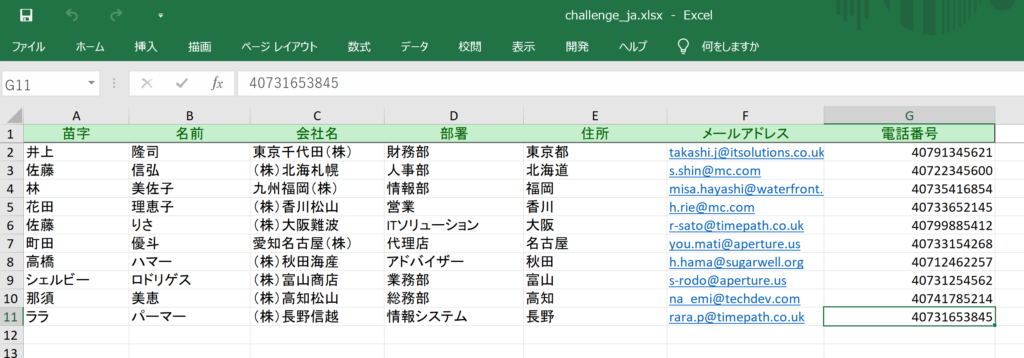
一見すると、これらをただ入力フォームに埋めて「登録」ボタンを押下するだけで簡単な問題に見えますが、「開始」ボタンを押してみると、、、

お気づきになられたでしょうか?何と、入力項目の位置関係が変わっているのです!!
ただ実際、Webアプリの自動化ではちょっとしたUIの変化でロボ(RPA)が正常に動作しないことは、しょっちゅうあります。
そういったUIの変化にも対応出来る柔軟なロボットでないと、この問題をクリア出来ないというところがポイントになっています。
UiPathではなくPythonで挑戦してみる
さて、本チャレンジはもともとUiPathを使用して問題を解けるかというものですが、本記事ではあえてUiPathではなくPythonを用いて挑戦してみたいと思います。
環境
- Windows 10
- Python 3.9.4
- Google Chrome : 90.0.4430.93
- chromedriver-binary : 90.0.4430.24.0
- pandas : 1.2.4
- openpyxl : 3.0.7
- selenium : 3.141.0
Pythonによる結果
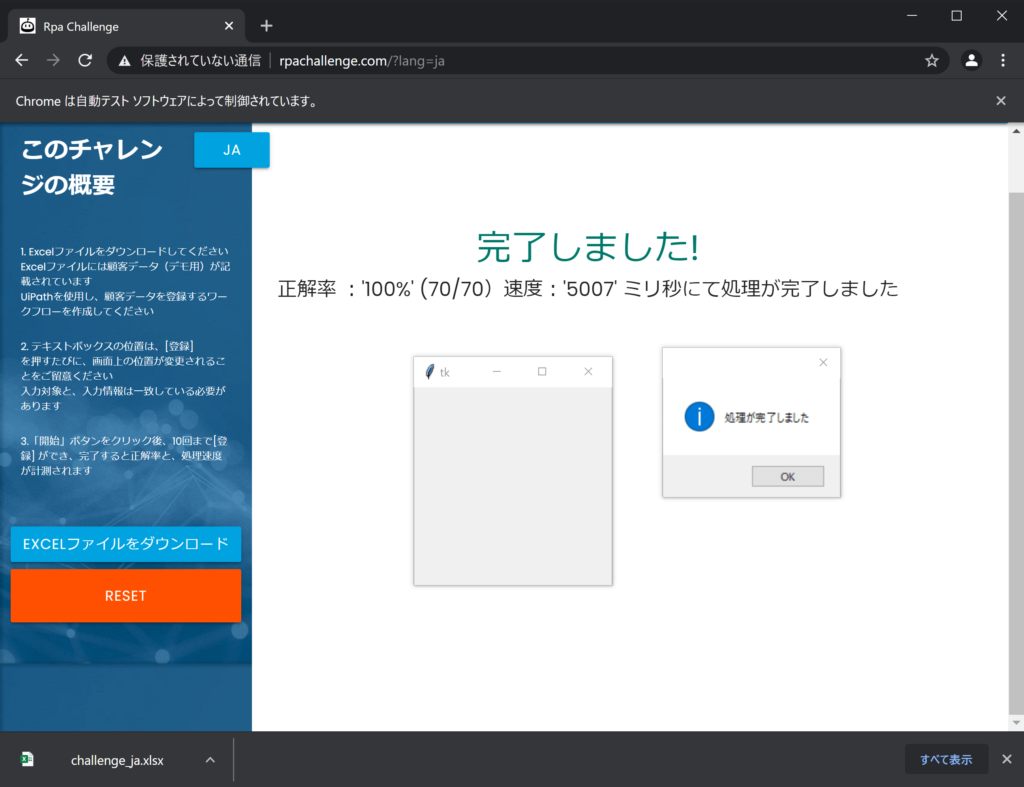
先ずは結果から。Sleepを入れないと動作が早すぎるので、敢えてSleepを仕込んでいます。

課題の解き方
通常、Webページの要素(正確にはタグ)には「ID」と呼ばれるそのページで一意に特定するための情報が付加されていることが多いです。
しかし、RPA Challengeではページをリロードする度にIDが変化してしまうため、IDで特定することは出来ません。
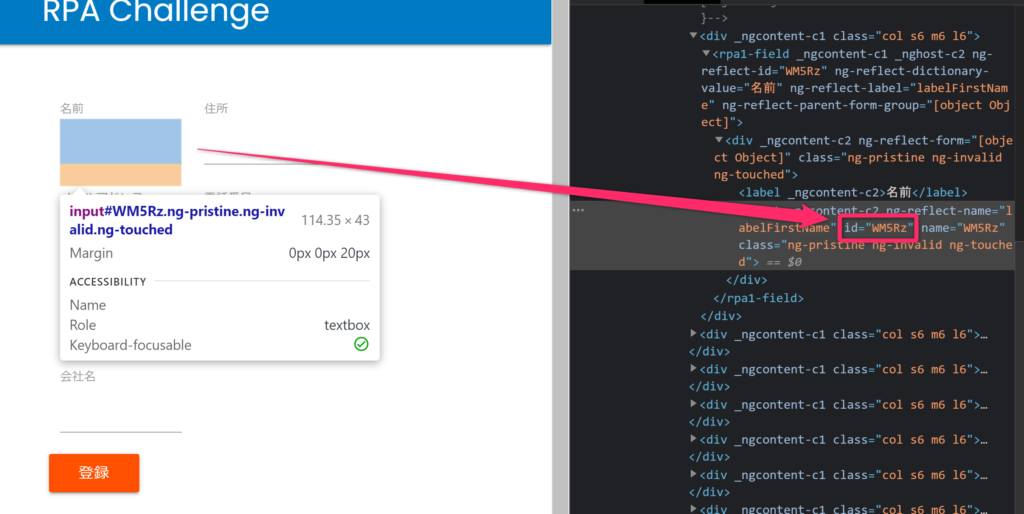
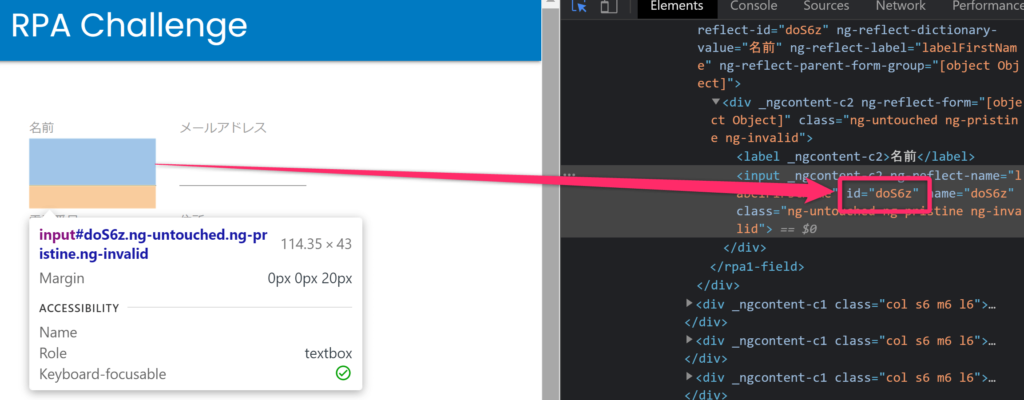
そこで、変わらないものは何かに着目するとラベルの名前は変わらないことと、ラベルの次に入力項目が来ることが分かります。
こちらはXPathを使うことで、解決出来ます。
ソースコード
ソースコードはこちら。RPA Challengeのページを開いてExcelファイルをダウンロードするところも自動操作出来るようにしています。
import os
import time
import glob
import pandas as pd
import numpy as np
import chromedriver_binary
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from tkinter import messagebox
driver = webdriver.Chrome()
driver.get(r'http://www.rpachallenge.com/?lang=ja')
WebDriverWait(driver, 10).until(
expected_conditions.visibility_of_element_located(
(By.XPATH, r'//a[contains(text(), "ダウンロード")]')
)
)
driver.find_elements_by_xpath(r'//a[contains(text(), "ダウンロード")]')[0].click()
download_path = os.environ['USERPROFILE'] + r'\Downloads'
target_filename = 'challenge_ja*.xlsx'
for i in range(10):
if glob.glob(f'{download_path}\\{target_filename}'):
break
time.sleep(1)
last_file = max(
glob.glob(f'{download_path}\\{target_filename}'), key=os.path.getctime)
df = pd.read_excel(last_file, sheet_name='Sheet1')
driver.find_elements_by_xpath(r'//button[text()="開始"]')[0].click()
for iRow, row in df.iterrows():
WebDriverWait(driver, 10).until(
expected_conditions.visibility_of_element_located(
(By.XPATH, r'//input[@value="登録"]')
)
)
time.sleep(0.5)
for column in row.keys():
if column.startswith('Unnamed'):
break
driver.find_elements_by_xpath(
f'//label[text()="{column}"]/following-sibling::input'
)[0].send_keys(row[column])
time.sleep(0.5)
driver.find_elements_by_xpath(r'//input[@value="登録"]')[0].click()
messagebox.showinfo('', '処理が完了しました')
# driver.quit()Sleepを外した結果・・・約5秒
Sleepを外した結果、5秒で処理が完了しました。処理間隔を短くしすぎるとサーバーに負荷をかけることになりますので、ご注意下さい。